

Chih-Yao Ma, Yannis Kalantidis, Ghassan AlRegib, Peter Vajda, Marcus Rohrbach, Zsolt Kira
European Conference on Computer Vision (ECCV), 2020
When automatically generating a sentence description for an image or video, it often remains unclear how well the generated caption is grounded, that is whether the model uses the correct image regions to output particular words, or if the model is hallucinating based on priors in the dataset and/or the language model. The most common way of relating image regions with words in caption models is through an attention mechanism over the regions that are used as input to predict the next word. The model must therefore learn to predict the attentional weights without knowing the word it should localize. This is difficult to train without grounding supervision since recurrent models can propagate past information and there is no explicit signal to force the captioning model to properly ground the individual decoded words. In this work, we help the model to achieve this via a novel cyclical training regimen that forces the model to localize each word in the image after the sentence decoder generates it, and then reconstruct the sentence from the localized image region(s) to match the ground-truth. Our proposed framework only requires learning one extra fully-connected layer (the localizer), a layer that can be removed at test time. We show that our model significantly improves grounding accuracy without relying on grounding supervision or introducing extra computation during inference, for both image and video captioning tasks.
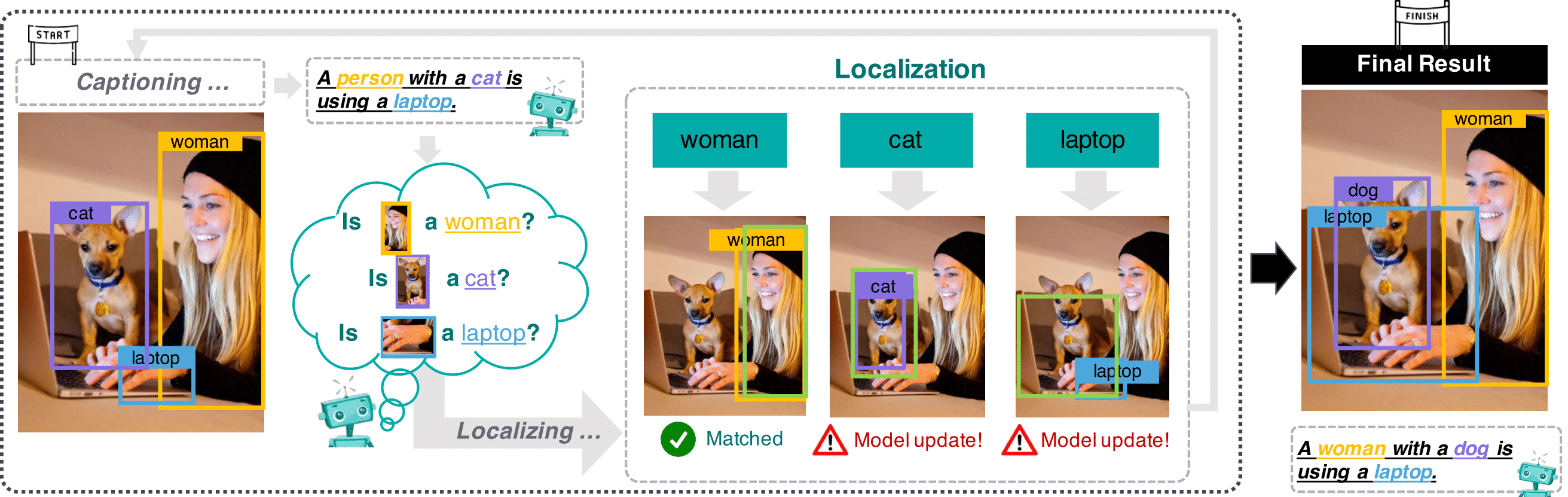
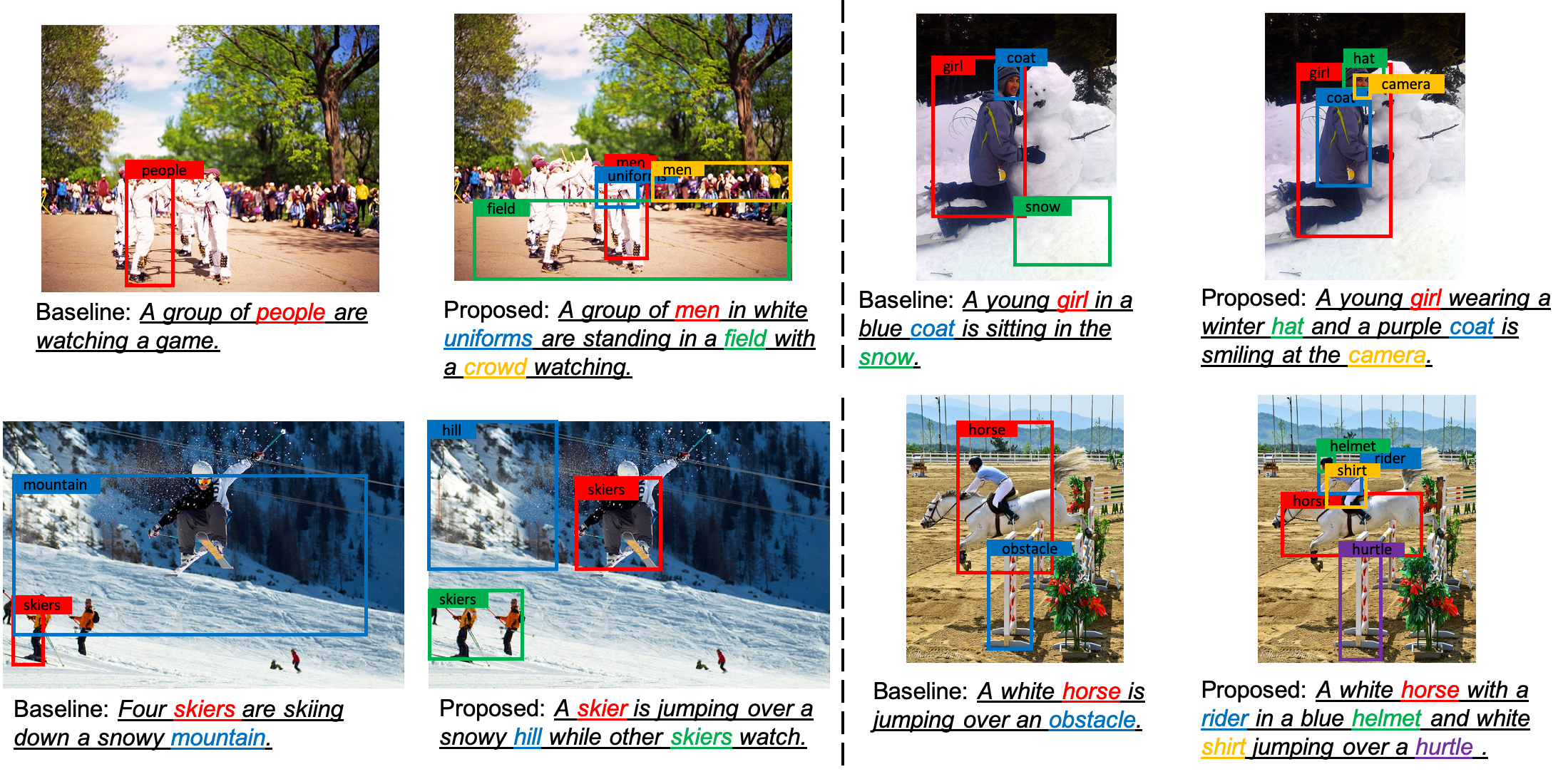
We conduct qualitative analysis for comparing the baseline (Unsup.) and the proposed method in the figure below. Each highlighted word has a corresponding image region annotated on the original image. The image regions are selected based on the region with the maximum attention weight. We can see that our proposed method significantly outperformed the baseline (Unsup.) in terms of both the quality of the generated sentence and grounding accuracy.
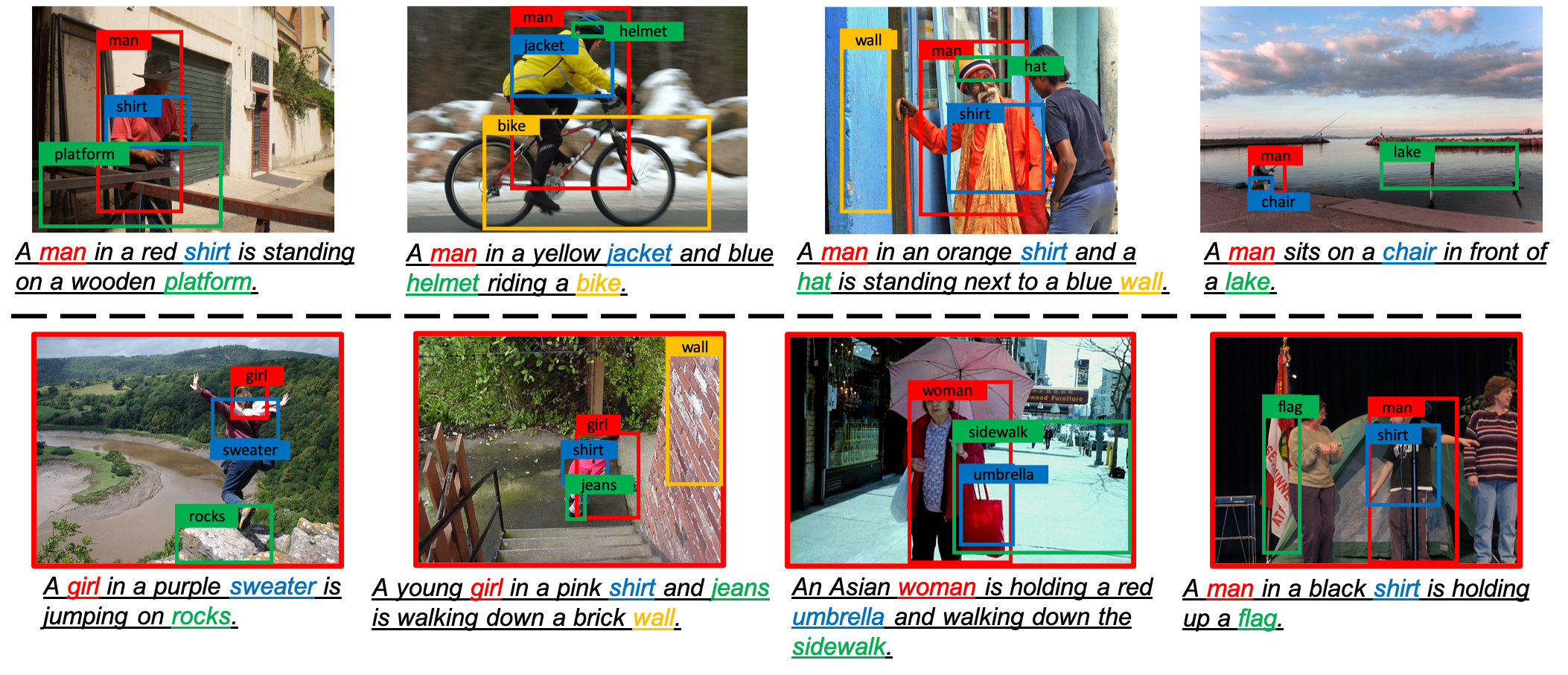
In addition, we also show a number of correct and incorrect examples of our proposed method in the figure below.
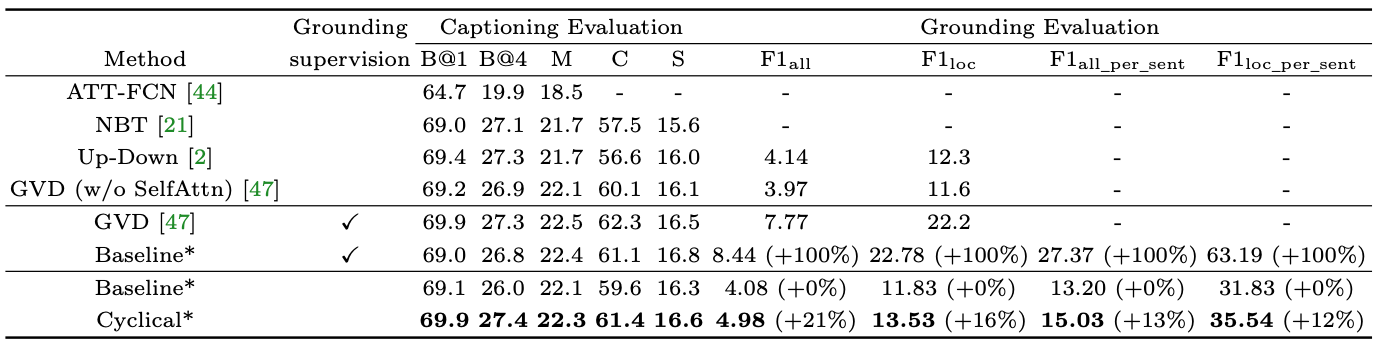
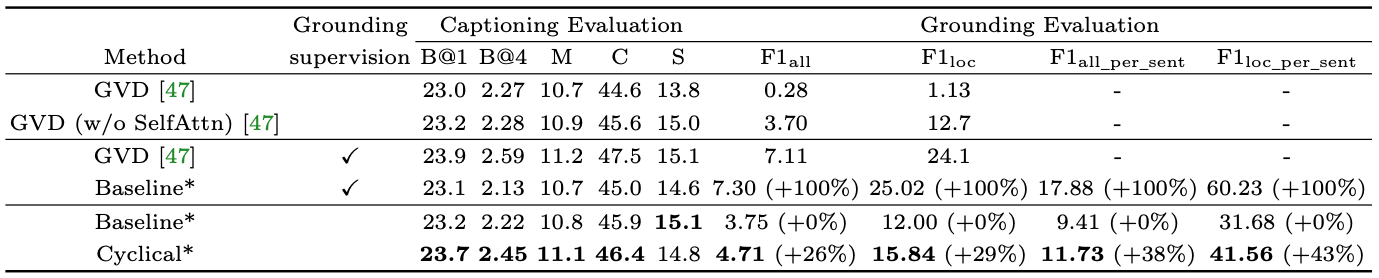
We first evaluate the proposed cyclical training regimen on the Flickr30k dataset for image captioning task. To understand how our proposed method performs on captioning as well as visual grounding, we compare with the proposed strong baseline with or without grounding supervision. We train the attention mechanism (Attn.) of the baseline method as well as adding the region classification task (Cls.) using the ground-truth grounding annotation. Using the resultant supervised baseline model as the upper bound, our proposed method with cyclical training achieves relative 20% to 15% grounding accuracy improvements for F1_all and F1_loc respectively and achieves around 12% improvements for F1_all_per_sent and F1_loc_per_sent, while maintaining the captioning evaluations performances.
Table 1: Performance comparison on the Flickr30k Entities test set. *: our results are averaged across five runs.
We also evaluate the proposed method on the ActivityNet-Entities dataset for video captioning task. Similarly, our proposed method significantly improve grounding accuracy while maintaining the captioning evaluations performances.
Table 2: Performance comparison on the Activity-Entities val set. *: our results are averaged across five runs.
If you find this work useful, please cite our paper:
@inproceedings{ma2020learning,
title={Learning to Generate Grounded Visual Captions without Localization Supervision},
author={Ma, Chih-Yao and Kalantidis, Yannis and AlRegib, Ghassan and Vajda, Peter and Rohrbach, Marcus and Kira, Zsolt},
booktitle={Proceedings of the European Conference on Computer Vision (ECCV)},
year={2020},
url={https://arxiv.org/abs/1906.00283},
}