



Chih-Yao Ma, Jiasen Lu, Zuxuan Wu, Ghassan AlRegib, Zsolt Kira, Richard Socher, Caiming Xiong
International Conference on Learning Representations (ICLR), 2019
(Top 7% of reviews)
[arXiv] [OpenReview] [GitHub] [Poster] [ML@GT]
The Vision-and-Language Navigation (VLN) task entails an agent following navigational instruction in photo-realistic unknown environments. This challenging task demands that the agent be aware of which instruction was completed, which instruction is needed next, which way to go, and its navigation progress towards the goal. In this paper, we introduce a self-monitoring agent with two complementary components: (1) visual-textual co-grounding module to locate the instruction completed in the past, the instruction required for the next action, and the next moving direction from surrounding images and (2) progress monitor to ensure the grounded instruction correctly reflects the navigation progress. We test our self- monitoring agent on a standard benchmark and analyze our proposed approach through a series of ablation studies that elucidate the contributions of the primary components. Using our proposed method, we set the new state of the art by a significant margin (8% absolute increase in success rate on the unseen test set).

We qualitatively show how the agent navigates through unseen environments by following instructions as shown in the figure below. In each figure, the agent follows the grounded instruction (at the top of the figure) and decides to move towards a certain direction (green arrow). For the full figures and more examples of successful and failed agents in both unseen and seen environments, please see the supplementary material in our paper.

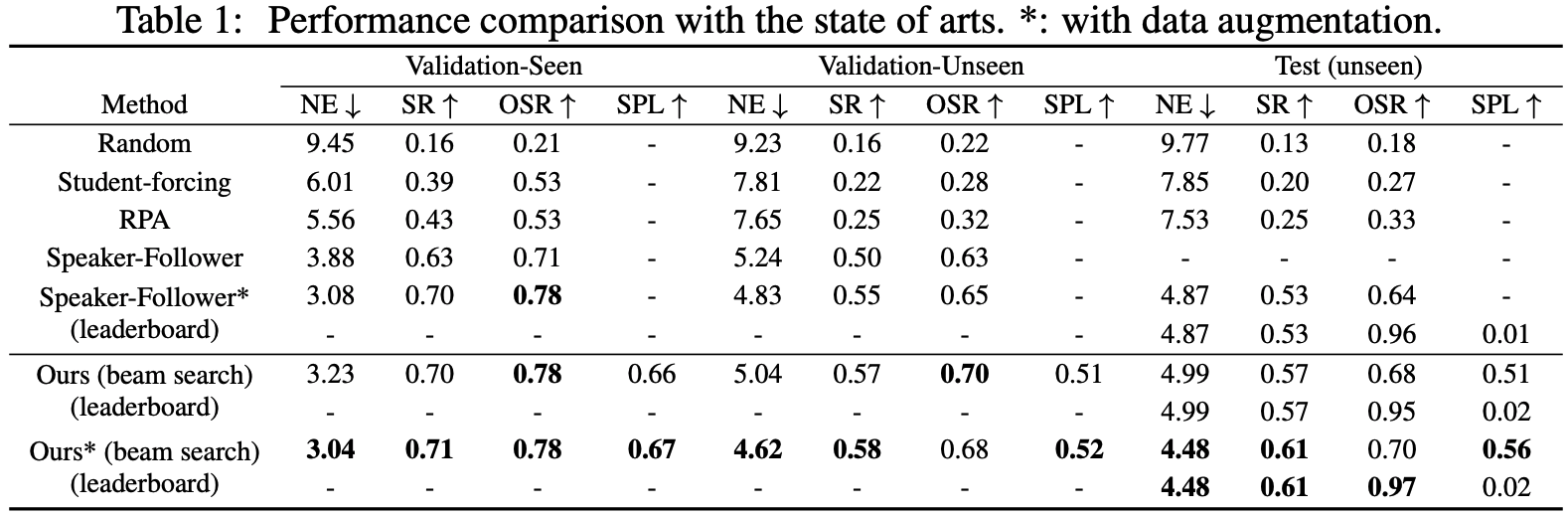
Our method achieves significant performance improvement compared to the state of the arts without data augmentation. We achieve 70% SR on the seen environment and 57% on the unseen environment while the existing best performing method achieved 63% and 50% SR respectively. When trained with synthetic data, our approach achieves slightly better performance on the seen environments and significantly better performance on both the validation unseen environments and the test unseen environments when submitted to the test server. We achieve 3% and 8% improvement on SR on both validation and test unseen environments. Both results with or without data augmentation indicate that our proposed approach is more generalizable to unseen environments.
If you find this work useful, please cite our paper:
@inproceedings{ma2019selfmonitoring,
title={Self-Monitoring Navigation Agent via Auxiliary Progress Estimation},
author={Ma, Chih-Yao and Lu, Jiasen and Wu, Zuxuan and AlRegib, Ghassan and Kira, Zsolt and Socher, Richard and Xiong, Caiming},
booktitle={Proceedings of the International Conference on Learning Representations (ICLR)},
year={2019},
url={https://arxiv.org/abs/1901.03035},
}